در این مقاله قصد داریم تا مفهوم یادگیری ماشین و عملکرد آن را به تفصیل شرح دهیم.machine learning (ML) زیرمجموعهای از هوش مصنوعی (AI) است و به فرآیند آموزش الگوریتمها برای یادگیری الگوها از دادههای موجود به منظور پیشبینی پاسخها بر روی دادههای جدید اشاره دارد.
اگرچه اصطلاحات AI و ML اغلب به جای یکدیگر استفاده میشونداما تفاوتهای مهمی بین این دو مفهوم وجود دارد. AI به فناوریای اشاره دارد که ماشینها را برای تقلید یا شبیهسازی فرآیندهای هوش انسانی در محیطهای واقعی آموزش میدهد، در حالی که یادگیری ماشین به سیستمهای رایانهای حاصله اشاره دارد که از دادههای موجود برای پیشبینی یاد میگیرند.
برای درک بهتر و کسب اطلاعات بیشتر همراه ما باشید.
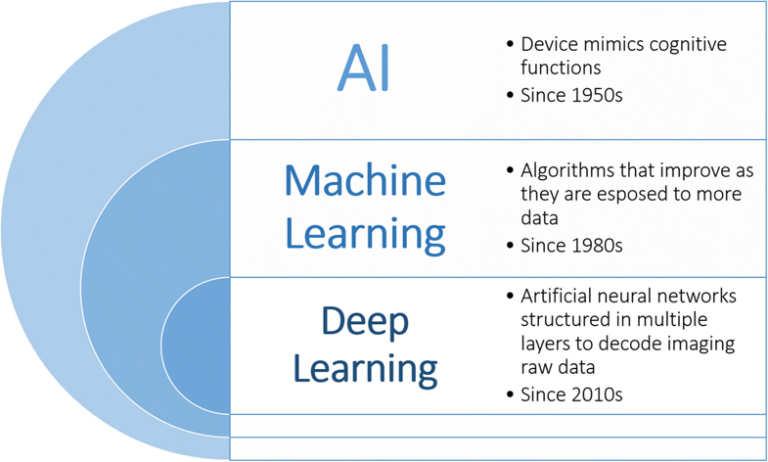 machine learning (ML) زیرمجموعهای از هوش مصنوعی (AI) است
machine learning (ML) زیرمجموعهای از هوش مصنوعی (AI) است
سه شکل رایج یادگیری ماشین (machine learning)
در اصل "یادگیری" به فرآیندی اشاره دارد که در آن مدلها توابع ریاضی را برای تبدیل دادههای زیربنایی به منظور پیشبینیهای دقیق ترسیم میکنند. در حالی که رایانهها را میتوان برای انجام کارهای ساده و قابل پیشبینی با پیروی از دستورالعملهای برنامهریزی شده یا زنجیرهای برنامهریزی کرد، مدلهای ML یک رویکرد کلی برای حل مسائل ایجاد میکنند.
در یادگیری ماشین سه شکل رایج وجود دارد که عبارتند از:
(یادگیری تحت نظارت) :Supervised learning
یادگیری نظارت شده زمانی اتفاق میافتد که یک مدل (ماشین) بر روی ورودیهای برچسبگذاری شده از داده و نتایج دلخواه آموزش داده میشود، جایی که هدف آموزش انجام یک کار در صورت ارائه دادههای جدید یا ناآشنا است.
در امنیت سایبری، یکی از کاربردهای رایج یادگیری تحت نظارت، آموزش مدلهای نمونههای مخرب است تا به آنها آموزش دهد تا پیشبینی کنند که آیا نمونههای جدید مخرب هستند یا خیر.
(یادگیری بدون نظارت) :Unsupervised learning
یادگیری ماشین بدون نظارت زمانی اتفاق میافتد که یک مدل بر روی دادههای بدون برچسب آموزش داده میشود و برای یافتن ساختار، روابط و الگوها در دادهها ، آزادانه عمل میکنند. در امنیت سایبری از این کلاس یادگیری برای کشف الگوهای حمله جدید یا رفتارهای متخاصم (به عنوان مثالanomaly detection) در مقیاس بزرگی از داده استفاده میشود.
(یادگیری تقویتی) :Reinforcement learning
یادگیری تقویتی زمانی اتفاق میافتد که به یک مدل، ورودی یا خروجی برچسب داده نمیشود و در عوض یادگیری از طریق آزمون و خطا انجام میشود و با فرایندهای تصمیمگیری متوالی سروکار دارد شامل یک عامل (Agent) و یک محیط (Environment) و یک مکانیزم بازخورد برای هدایت اقدامات عامل است که عامل در این فرایند یاد میگیرد که با تعامل با محیط تصمیم گیری کند و در ازای آن پاداش دریافت کند که هدف از این اقدامات به حداکثر رساندن پاداش انباشته توسط عامل است. این شکل از یادگیری ماشین نحوه یادگیری انسان رااز نزدیک تقلید میکند و بهویژه در شناسایی راههای خلاقانه و نوآورانه برای حل مشکلات کاربرد زیادی دارد. برخی از کاربردهای یادگیری تقویتی در امنیت سایبری شامل راهحلهایی برای سیستمهای فیزیکی-سایبری، تشخیص نفوذ مستقل و حملات DDOS است.
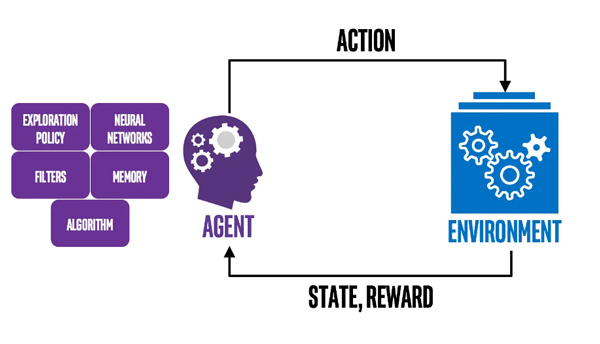
یادگیری ماشین دارای طیف وسیعی از موارد استفاده در فضای امنیت سایبری است
مزایای یادگیری ماشین (machine learning) در امنیت سایبری
ترکیب حجم زیادی از دادهها با سرعت بالا
یکی از بزرگترین چالشهایی که تحلیلگران با آن مواجه هستند، نیاز به ترکیب سریع اطلاعات تولید شده در سطح حمله آنها است، که معمولاً بسیار سریعتر از آن چیزی است که تیم تحلیلگران بتوانند به صورت دستی پردازش کنند. یادگیری ماشین قادر است حجم زیادی از اطلاعات تاریخچهای و پویا را به سرعت تجزیه و تحلیل کند و تیمها را قادر میسازد از این دادهها به صورت real-time در محیط عملیاتی استفاده کنند.
فعالسازی هوش متخصص در مقیاس مناسب
چرخههای آموزشی منظم به مدلها این امکان را میدهد که به طور مداوم از جمعیت نمونه در حال تکامل خود یاد بگیرند، که شامل تشخیصهای برچسبگذاری شده یا هشدارهای بررسی شده توسط تحلیلگران است. این کار از تکرار موارد مثبت کاذب (false positives) جلوگیری میکند و مدلها را قادر میسازد تا واقعیت تولید شده توسط متخصصان را بیاموزند و به اجرا بگذارند
پویا کردن taskهای تکراری و دستی
بهکارگیری یادگیری ماشین برای taskهای خاص میتواند به تیمهای امنیتی به منظور جلوگیری از انجام دستی و چندباره taskهای روزمره و تکراری کمک کند و به عنوان یک نیروی تقویت کننده آنها را قادر سازد تا به هشدارهای دریافتی در مقیاسهای بزرگتر پاسخ دهند و از زمان و منابع خود در پروژههای پیچیده و استراتژیک دیگری استفاده کنند.
افزایش بازده تحلیلگران
یادگیری ماشین میتواند بینش تحلیلگران را با اطلاعات به روز و به صورت real-time تقویت کند و به آنها این امکان را بدهد تا در عملیاتهای امنیتی و جستوجوی تهدید، منابع خود به صورت موثر و مفید برای رسیدگی به آسیبپذیریهای حیاتی سازمان خود اولویتبندی کنند و ابتدا به شناسایی و بررسی هشدارهای حساس به زمان (time-sensitive) رسیدگی کنند.
 از رایجترین کاربردهای یادگیری ماشین در امنیت سایبری، طبقه بندی بدافزارها است
از رایجترین کاربردهای یادگیری ماشین در امنیت سایبری، طبقه بندی بدافزارها است
موارد استفاده از یادگیری ماشین (machine learning) در امنیت سایبری
یادگیری ماشین دارای طیف وسیعی از موارد استفاده در فضای امنیت سایبری است. میتوانیم این موارد استفاده را به دو گروه اصلی تقسیم کنیم :
شناسایی و پاسخ خودکار تهدید (Automated threat detection and response)
در دسته اول، یادگیری ماشینی سازمانها را قادر میسازد تا کار دستی را به صورت خودکار انجام دهند. به ویژه در فرآیندهایی که حفظ سطوح بالایی از دقت و سرعت پاسخگویی در سطح ماشین ضروری است مانند تشخیص و پاسخ خودکار تهدید (automatic threat detection and response) یا طبقهبندی الگوهای جدید دشمن.
استفاده به عنوان ابزار کمکی در عملیاتهایی که توسط تحلیلگر انجام میشود (Analyst-led operations)
مدلهای یادگیری ماشینی همچنین میتوانند با هشدار دادن به تیمهادر مورد تهدیدات و یا مشخص کردن آسیبپذیریهای اولویتدار به تحقیقات تحلیلگر کمک کنند. بررسی تحلیلگر میتواند به ویژه در سناریوهایی که دادههای کافی برای مدلها برای پیشبینی نتایج با درجهای از اطمینان بالا یا بررسی رفتارهای خوشخیم که ممکن است توسط طبقهبندیکنندههای بدافزار بدون هشدار باقی بماند، ارزشمند باشد.
دیگر موارد استفاده از یادگیری ماشین (machine learning) در امنیت سایبری
- Vulnerability Management
لیستی از اولویتبندی آسیبپذیریهای موجود را بر اساس اهمیت، برای تیمهای فناوری اطلاعات و امنیت فراهم میکند.
2. Static File Analysis
با پیشبینی مخرب بودن فایل بر اساس ویژگیهای یک فایل، از تهدیدات پیشگیری میکند.
3. Behavioral Analysis
رفتار دشمن را برای مدلسازی و پیشبینی الگوهای حمله در طول زنجیره کشتار سایبری (cyber kill chain) تحلیل میکند.
4. Static & Behavioral Hybrid Analysis
قابلیتهای Static File Analysis و Behavioral Analysis را به منظور تشخیص تهدیدات به صورت پیشرفته با هم ترکیب میکند.
5. Anomaly Detection
ناهنجاریها را در دادهها شناسایی میکند تا از رتبه بندی تهدیدات (risk scoring) و هدایت تحقیقات به سمت تهدید استفاده کند.
6. Forensic Analysis
فرایندضدجاسوسی (مجموعۀ فعالیتهای مربوط به حفظ و حراست اطلاعات و جلوگیری از به سرقت رفتن یا درزکردن آنها) را برای تجزیه و تحلیل پیشرفت حمله و شناسایی آسیبپذیریهای سیستم اجرا میکند.
7. Sandbox Malware Analysis
نمونه کدها را در محیطهای ایمن و ایزوله تجزیه و تحلیل میکند تا رفتارهای مخرب را شناسایی و طبقهبندی کند، و همچنین آنها را برای دشمنان شناخته شده ترسیم میکند.
ارزیابی کارایی مدلهای ماشین برای طبقهبندیکنندههای بدافزار
از رایجترین کاربردهای یادگیری ماشین در امنیت سایبری، طبقه بندی بدافزارها است. طبقهبندیکنندههای بدافزار یک "پیشبینی امتیازی" در مورد مخرب بودن یک نمونه ارائه میدهند که این امتیاز به سطح اطمینان مرتبط با طبقهبندی حاصل اشاره دارد. یکی از روشهایی که بهوسیله آن عملکرد این مدلها را ارزیابی میکنیم، نمایش پیشبینیها در دو محور است :
1. دقت (این که آیا یک نتیجه به درستی طبقهبندی شده است؛ "درست" یا "نادرست")
2. خروجی (کلاسی که یک مدل به یک نمونه اختصاص میدهد؛ "مثبت" یا "منفی")
توجه داشته باشید که عبارات مثبت و منفی در این چارچوب به این معنی نیست که یک نمونه به ترتیب بی خطر یا مخرب است. اگر یک طبقهبندیکننده بدافزار تشخیص مثبت انجام دهد، این نشان میدهد که مدل بر اساس مشاهده ویژگیهای مرتبط که از نمونههای مخرب شناخته شده یاد گرفته است، پیشبینی میکند که یک نمونه مشخص مخرب است.
برای نشان دادن معنای این گروهبندیها، از نمونه مدلهایی استفاده میکنیم که برای تجزیه و تحلیل فایلهای مخرب استفاده میشوند.
- True Positive: مدل به درستی یک فایل مخرب را پیشبینی کرد.
- True Negative: مدل به درستی پیشبینی کرد که یک فایل مخرب نیست.
- False Positive: مدل به اشتباه پیشبینی کرد که یک فایل مخرب است.
- False Negative: مدل به اشتباه پیشبینی کرد که یک فایل مخرب نیست.
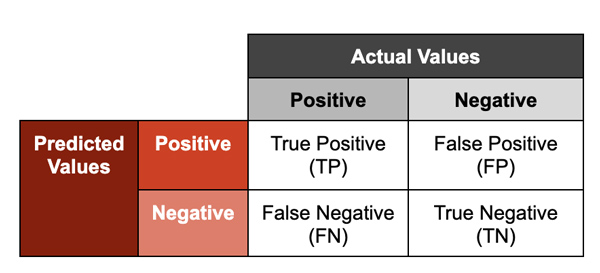
اگرچه true positives برای تشخیص تهدید و پاسخ (threat detection and response) ضروری هستند، false positives نیز معیار مهمی برای عملکرد مدل هستند. موارد false positiveدارای "هزینه فرصت از دست رفته" (opportunity cost) هستند که مربوط به زمان و منابعی است که تیمهای امنیتی برای بررسی هر شناسایی صرف میکنند. و همچنین اگر فرآیندهای اصلاح خودکار به منظور مسدود یا مختل کردنبرنامههایی که برای عملیاتهای سازمانی حیاتی هستند در نظر گرفته شود نیز میتواند به طور ویژه ای پر هزینه باشد.
متخصصین علوم داده باید برای هر دو نرخtrue positive و false positiveرا بهینهسازی کنند و برای این کار با یک مبادله حیاتی مواجه هستند :
کاهش آستانه برای true positive (یعنی الزاماتی که برای طبقهبندی یک مدل باید برآورده شود تا یک نمونه را به عنوان یک فایل مخرب طبقهبندی کند) با خطر کاهش آستانه false positive نیز همراه است (که میتواند منجر به کاهش بهرهوری تحلیلگر میشود). ما به این مبادله با عنوان اثربخشی تشخیص اشاره (detection efficacy)میکنیم.
هدف نهایی ساخت مدلهای یادگیری ماشین با کارایی بالا، به حداکثر رساندن اثربخشی تشخیص است که به معنی به حداکثر رساندن تشخیصهای true positive در حالی که موارد false positive را به حداقل میرسانند. برای نشان دادن پیچیدگی این تعادل، در نظر بگیرید که برای طبقهبندی کنندههای بدافزار غیرمعمول نیست که نرخهای true positive نزدیک به 99 درصد و در مقابل نرخهای false positive بسیار کمتر از 1 درصد متعادل شوند.
 متخصصین علوم داده باید برای هر دو نرخtrue positive و false positiveرا بهینهسازی کنند
متخصصین علوم داده باید برای هر دو نرخtrue positive و false positiveرا بهینهسازی کنند
چالشها و محدودیتهای یادگیری ماشین (machine learning)
در حالی که مدلهای یادگیری ماشین میتوانند ابزار قدرتمندی باشند، هر مدلی تحت محدودیتهای منحصربهفردی عمل میکند:
دادههای با کیفیت بالای کافی
آموزش مدلهای با اطمینان بالا اغلب نیاز به دسترسی به مجموعه دادههای بزرگ، هم برای آموزش و هم برای آزمایش مدلهای یادگیری ماشینی دارد. برای آزمایش مدلها، زیرمجموعهای از دادهها معمولاً از مجموعه آموزشی برای آزمایش عملکرد مدل کنار گذاشته میشوند. این داده ها باید دارای حداقل همپوشانی ویژگی با دادههای آموزشی باشد. به عنوان مثال، نشان دهنده یک بازه زمانی متفاوت از جمعآوری دادهها یا نشات گرفته از یک منبع داده متفاوت است. اگر دادههای با کیفیت بالا کافی وجود نداشته باشد، ممکن است یک فضای مشکل معین سناریوی مناسبی برای یادگیری ماشین نباشد.
مبادله بین true positive و false positive
همانطور که قبلاً بحث شد آستانه تشخیص بین true positive و false positive باید متعادل شود تا کارایی تشخیص به حداکثر برسد.
توضیحپذیری
توضیحپذیری به توانایی توضیح چگونگی و چرایی عملکرد یک مدل اشاره داردو به تیمهای متخصص علوم داده امکان درک ویژگیهایی که در یک نمونه بر عملکرد مدل تأثیر میگذارد را میدهد. توضیحپذیری برای ایجاد مسئولیتپذیری، ایجاد اعتماد، حصول اطمینان از انطباق با خطمشیهای داده و در نهایت، امکان بهبود مستمر عملکرد یادگیری ماشین بسیار مهم است.
تکرارپذیری
به توانایی آزمایشهای یادگیری ماشینی برای بازتولید مداوم اشاره دارد. تکرارپذیری در مورد نحوه استفاده از یادگیری ماشینی، نوع مدلهایی که استفاده میشوند، اینکه بر روی چه دادههایی آموزش دیدهاند و در چه محیطها یا نسخههای نرمافزاری کار میکنند، شفافیت ایجاد میکند. تکرارپذیری ابهام و خطاهای احتمالی را همراه با تبدیل مدلها از نمونههای آزمایشی به حالت پیادهسازی واقعی و از طریق چرخههای بهروزرسانیهای آتی به حداقل میرساند.
بهینهسازی برای محیط هدف
هر مدل باید برای محیط تولید هدف خود بهینه شود. هر محیطی از نظر در دسترس بودن منابع محاسباتی، حافظه و دسترسیپذیری متفاوت است. متعاقباً، هر مدل باید طوری طراحی شود که در محیط استقرار خود، بدون ایجاد فشار یا وقفه در عملیات میزبان هدف، عمل کند.
سخت شدن (Hardening) در برابر حملات متخاصم
مدلهای یادگیری ماشین سطح حمله خاص خود را دارند که میتواند در برابر حملات دشمن آسیبپذیر باشد، جایی که دشمنان ممکن است سعی کنند از رفتار مدل سوءاستفاده یا آن را اصلاح کنند. برای به حداقل رساندن سطح حمله قابل بهرهبرداری مدلها (exploitable attack)، متخصصین علوم داده مدلها را در آموزش "سخت" (harden) میکنند تا از عملکرد قوی و انعطافپذیری در برابر حملات اطمینان حاصل کنند.
تصورهای غلط در مورد یادگیری ماشین (machine learning)
یادگیری ماشینی بهتر از روشهای تحلیلی یا آماری مرسوم است :
اگرچه یادگیری ماشین میتواند ابزار بسیار موثری باشد، اما ممکن است برای استفاده در هر فضای مسئلهای مناسب نباشد. سایر روشهای تحلیلی یا آماری ممکن است نتایج بسیار دقیق و مؤثرتری تولید کنند یا نسبت به رویکرد یادگیری ماشینی کمتر به منابع نیاز داشته باشند و برای یک فضای مسئلهای معین رویکرد مناسبتری داشته باشند.
یادگیری ماشینی باید برای خودکارسازی هر چه بیشتر وظایف (tasks) استفاده شود:
یادگیری ماشینی میتواند وابسته به منابع زیادی باشد و اغلب نیاز به دسترسی به مقادیر زیادی داده، منابع محاسباتی و تیمهای اختصاصی علوم داده برای ساخت، آموزش و نگهداری مدلها داشته باشد. برای به حداکثر رساندن بازگشت سرمایه (ROI) در نگهداری مدلها، زمانی که مشکلات هدف، ارزش بالا و نیاز به سرعت و دقت زیادی دارند و دارای مجموعه دادههای باکیفیت کافی برای آموزش و آزمایش مداوم هستند، بهترین کاربرد را دارد.
یادگیری ماشین(Machine Learning) بهطور مداوم در حال رشد است
جمعبندی
امروزه یادگیری ماشین(Machine Learning) بهطور مداوم در حال رشد است و بههمین سبب، کاربردهای آن نیز در حال توسعه بوده و روز به روز بیشتر در زندگی ما نقش خواهد داشت. در این مقاله دریافتیم که یادگیری ماشین یکی از زیرمجموعههای هوش مصنوعی است و به برنامهها این امکان را میدهد تا بتوانند به دادهها دسترسی پیدا کرده و از آنها برای یادگیری استفاده کنند. ما در این مطلب مفصل توضیح دادیم یادگیری ماشین چیست و کاربردها، چالشها و مزایای آن را بررسی کردیم.